Penney’s Game, loosely, is a game about waiting for particular sequences of coin throws inside a larger sequence of fair coin throws. In our first foray into the topic, we examined head-to-head matchups between sequences of three coins. That is, you and a friend both choose a sequence of three coin flips, and the winner is determined by whose sequence appears first.
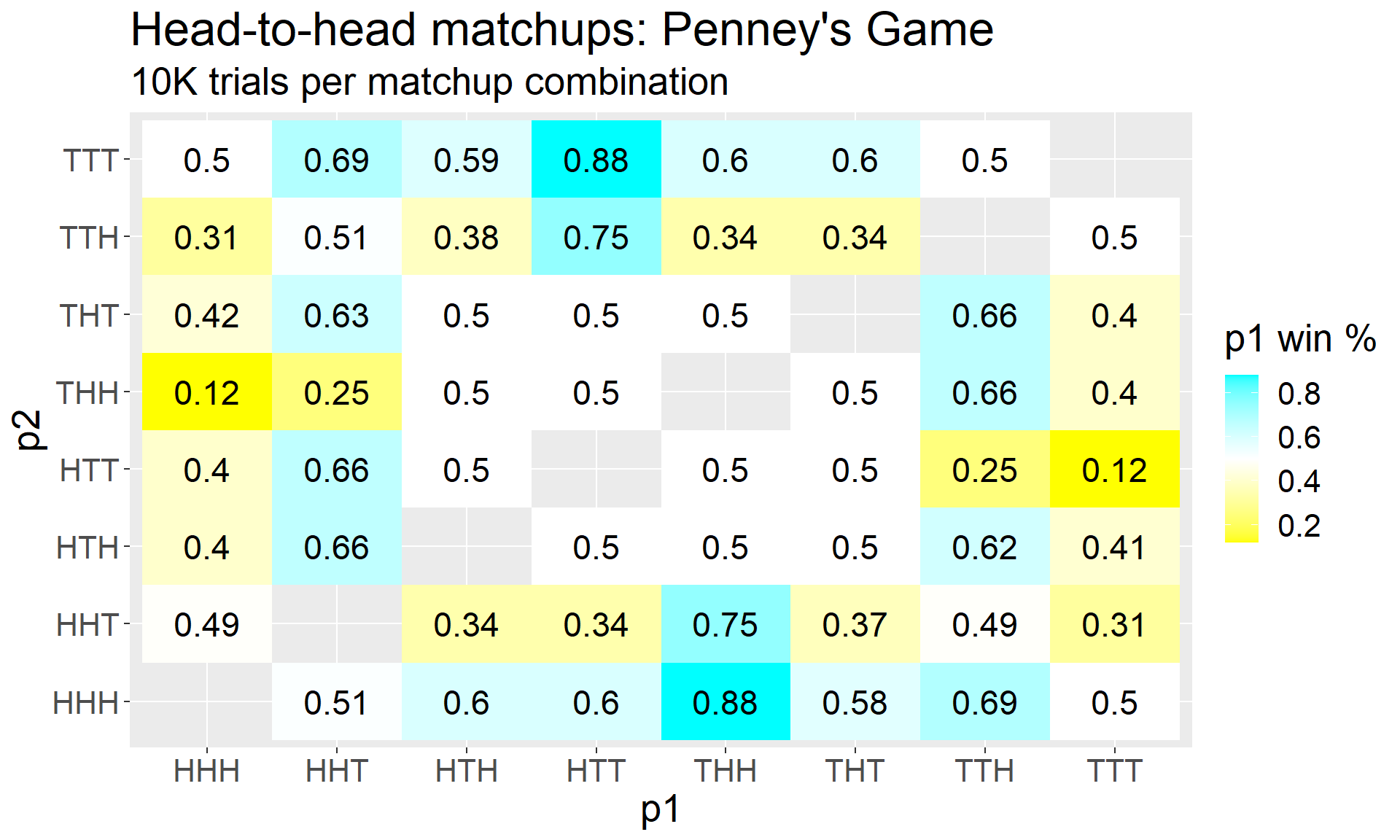
The first surprising result about this game – or at least, surprising if your intuition is anything like mine was – is that this game is far from fair, and that the win probabilities depend highly on which sequences are chosen.
(NB: I’ve collapsed the code below since it showed up in a nearly-identical form in a previous post, but you can view it by clicking the “Code” button.)
Show code
library(ggplot2)library(dplyr)library(tidyr)library(stringr)#-------------------# This function will take two strings of coin flips and return the one that occurs# first in a long sequence of coin flips.penney <-function(p1, p2){ # p1 and p2 are strings like "HHT", "HTT" coins <-nchar(p1) # record how many coins are in the sequences to be compared p1 <-unlist(str_split(p1, "")) # split string into vector of length equal to coins p2 <-unlist(str_split(p2, "")) flips <-sample(c("H", "T"), coins, replace = T) # on each pass of the while loop, push the first n-1 coins forward in the list,# then sample a new coin for the nth one; for instance, HTH becomes TH? where# ? is the result of a new coin flipwhile(!all(p1 == flips) &!all(p2 == flips)){ flips[1:(coins -1)] <- flips[2:coins] flips[coins] <-sample(c("H", "T"), 1) }ifelse(all(p1 == flips), paste0(p1, collapse =""), paste0(p2, collapse ="")) # output winning sequence}#-------------------# This helper function takes two coin sequences, simulates Penney's game many# times, and returns the proportion of times the *first* sequence wins.penney_wrapper <-function(p1, p2){mean(replicate(1e4, penney(p1, p2)) == p1)}# The next function produces a vector of appropriate length enumerating all# possible sequences of coin flips of that length; for instance, ht_iterator(2)# will return the vector c("HH", "HT", "TH", "TT"). This works recursively by # calling ht_iterator(k-1), duplicating it, and appending each of H and T to # one of the duplicates.ht_iterator <-function(k){if(k ==1) {return(c("H", "T")) } else {ht_iterator(k-1) %>%rep(each =2) %>%paste0(c("H", "T")) } }# make a data frame with all combinations of sequencesresults <-ht_iterator(3) %>%combn(2) %>%t() %>%as.data.frame()names(results) <-c("p1", "p2")results <- results %>%rowwise() %>%mutate(p1_wins =penney_wrapper(p1, p2)) %>%mutate(p1_wins =round(p1_wins, 2))# since we simulated only half of the matchups, we can just mirror# the results to flip p1 and p2 rather than resimulatingresults <-tibble(p1 = results$p2,p2 = results$p1,p1_wins =1- results$p1_wins ) %>%bind_rows(results)results %>%ggplot(aes(x = p1, y = p2, fill = p1_wins)) +geom_tile() +geom_text(aes(label = p1_wins), size =6) +scale_fill_gradient2(low ="yellow", mid ="white", high ="cyan", midpoint =0.5) +labs(title ="Head-to-head matchups: Penney's Game",subtitle ="10K trials per matchup combination",fill ="p1 win %") +theme(text =element_text(size =20))
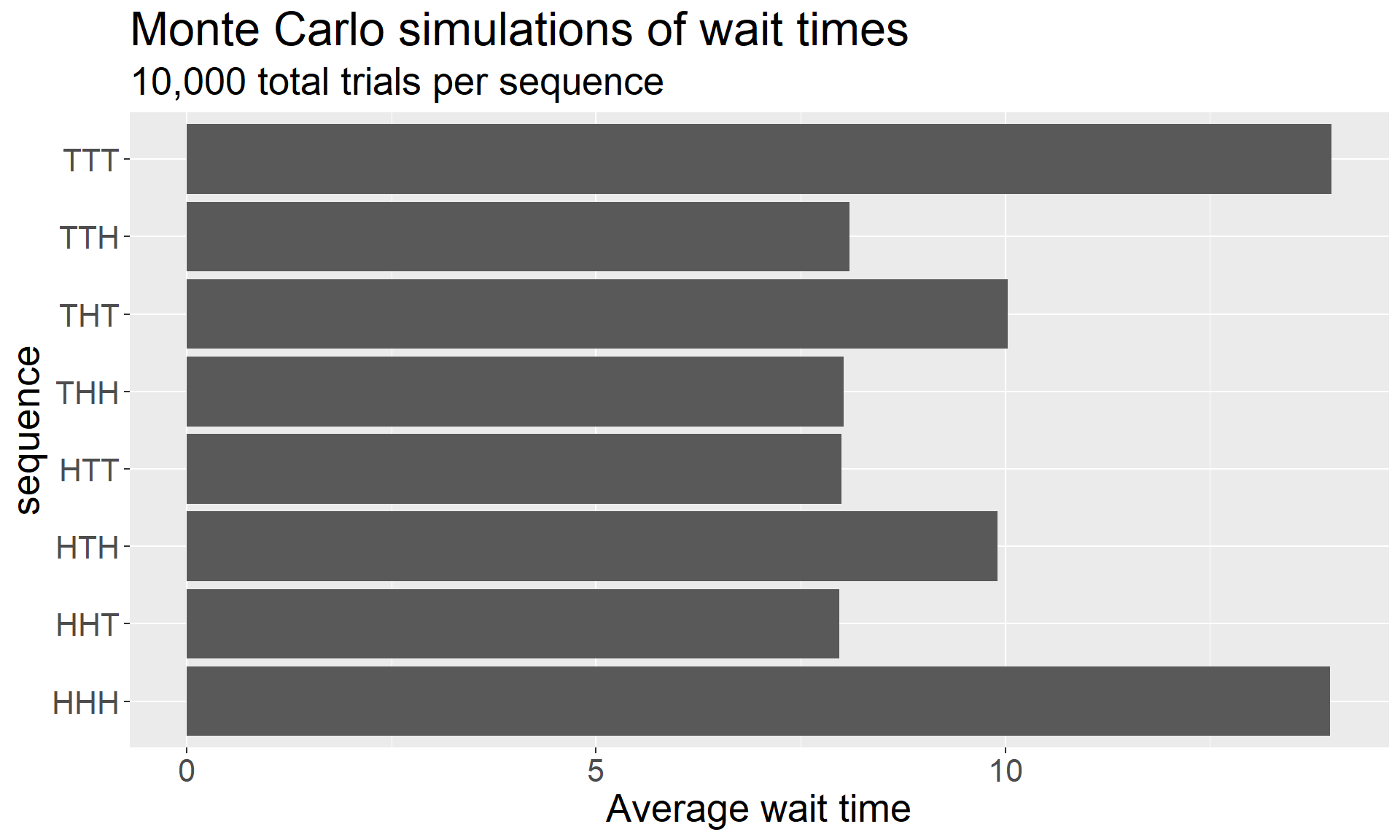
Next, we explored a non-competitive variant of this game in which a player waits for a sequence to appear. Like before, the result that many find counterintuive at first – and I very much include myself in that group – is that the expected wait time depends on the sequence chosen. (As before, I’ve obscured the code since it appeared in a nearly-identical form in a previous post, but you can click the button below if you want to see it.)
Show code
penney_wait <-function(p1){ # p1 is a string like "HHT" coins <-nchar(p1) # keep track of how many coins needed p1 <-unlist(str_split(p1, "")) # split string into vector w/ length == coins flips <-sample(c("H", "T"), coins, replace = T) num_flips <- coins # keep track of how many flips have happened# on each pass of the while loop, push the first n-1 coins forward in the list,# then sample a new coin for the nth one; for instance, HTH becomes TH? where# "?" is the result of a new coin flipwhile(!all(p1 == flips)){ flips[1:(coins -1)] <- flips[2:coins] flips[coins] <-sample(c("H", "T"), 1) num_flips <- num_flips +1 } num_flips # return number of flips required}tibble(sequence =ht_iterator(3)) %>%rowwise() %>%mutate(avg_wait =mean(replicate(1e4, penney_wait(sequence)))) %>%ggplot(aes(x = sequence, y = avg_wait)) +geom_bar(stat ="identity") +labs(title ="Monte Carlo simulations of wait times",subtitle ="10,000 total trials per sequence",y ="Average wait time") +theme(text =element_text(size =20)) +coord_flip()
Of course, there are good reasons for these phenomena. As with any interesting mathematical question, you can go through the calculations to verify these facts. And yet, in my experience, most people (mathematicians and non-mathematicians alike) crave an intuitive understanding of the problems that lives on a different plane from the calculations and proof.
When I was first becoming accommodated with Penney’s Game, I reconciled the two graphs above by concluding that coin sequences are naturally tiered. From the graph of average wait times, we see a suggested hierarchy:
ranking
sequences
slow
HHH, TTT
medium
HTH, THT
fast
HHT, HTT, THH, TTH
Indeed, from examining the graph of head-to-head win probabilities, we see that this is indeed the case; all “fast” sequences carry at least a \(50\%\) win rate over all “medium” and “slow” sequences, and all “medium” sequences also hold this over the “slow” sequences.
I found this to be quite satisfying, and it led me to wonder: In Penney’s Game, do sequence structures always give rise to this type of hierarchy of both expected values and competitive advantages?
The Incorrect Answer
It’s probably clear where I’m heading with this, right? This conjecture seemed completely reasonable to me. I assumed that sequences with lower expected wait times would always have competitive advantages (or at least be fair propositions) against sequences with higher expected wait times.
The Correct Answer
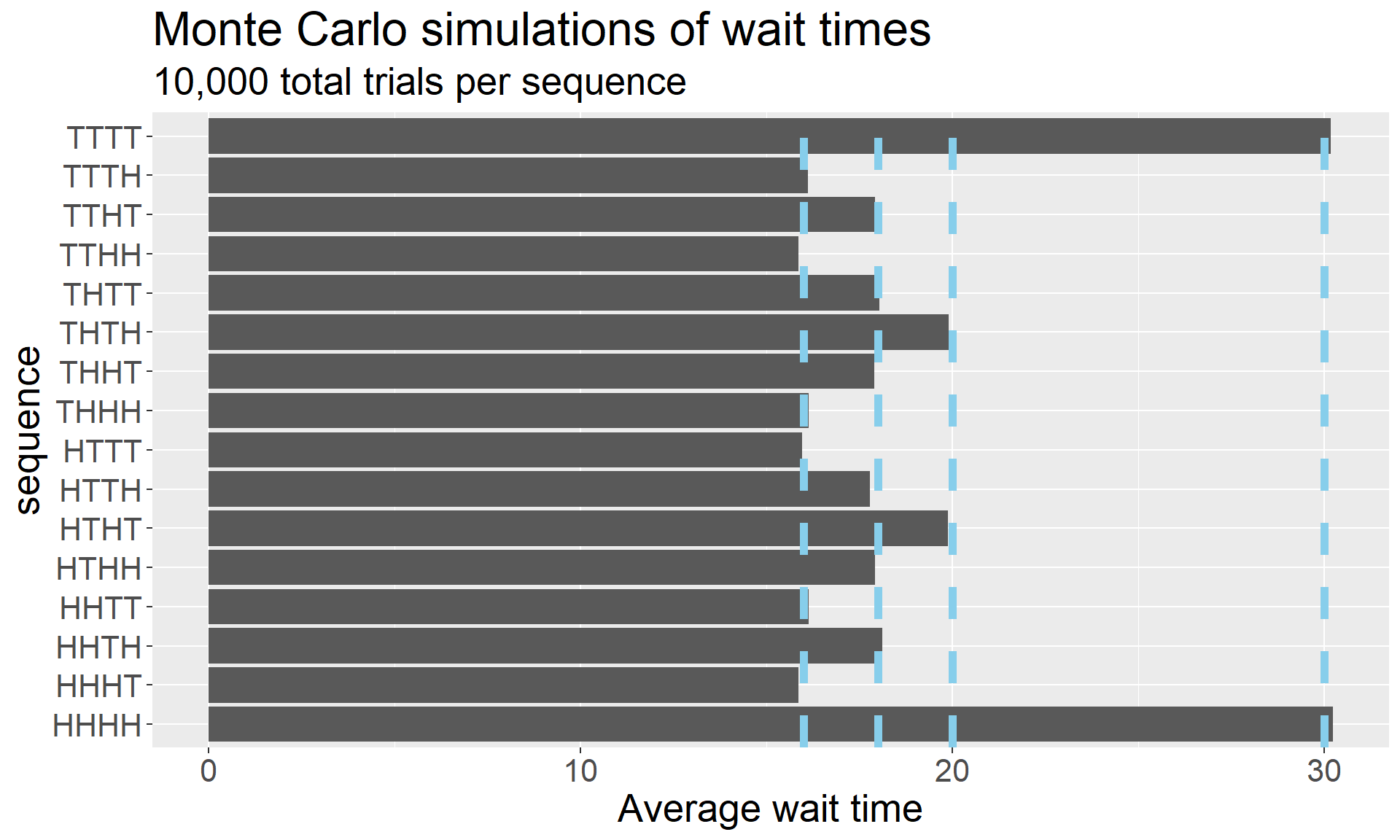
There are no hierarchies here, because Penney’s Game is a place where reasonable conjectures go to die. Let’s have a look at the expected wait times for the four-coin version of the game:
# ht_iterator() is defined in the first collapsed code block above# penney_wait() is defined in the second collapsed code block abovetibble(sequence =ht_iterator(4)) %>%rowwise() %>%mutate(avg_wait =mean(replicate(1e4, penney_wait(sequence)))) %>%ggplot(aes(x = sequence, y = avg_wait)) +geom_bar(stat ="identity") +labs(title ="Monte Carlo simulations of wait times",subtitle ="10,000 total trials per sequence",y ="Average wait time") +theme(text =element_text(size =20)) +coord_flip() +geom_hline(yintercept =c(16, 18, 20, 30), lty =2, lwd =2, color ="skyblue")
One of the challenges of the Monte Carlo approach is that the bars in the graph fluctuate a bit based on the random simulations, and it can be tough to determine what the exact values are visually. However, by a theorem (one that has not appeared in these notes… yet), the true expected wait times of each of these sequences is an even integer.
That fact is enough to deduce the true expected wait times despite the fluctuations from simulations. Vertical lines on the graph above have been superimposed at positions \(x = 16, 18, 20, 30\). That is:
sequences
expected wait time
tier
TTTT, HHHH
30
slowest
HTHT, THTH
20
med. slow
TTHT, THTT, THHT, HTTH, HTHH, HHTH
18
med. fast
TTTH, TTHH, THHH, HTTT, HHTT, HHHT
16
fastest
If a hierarchy exists, this is what it would have to be.
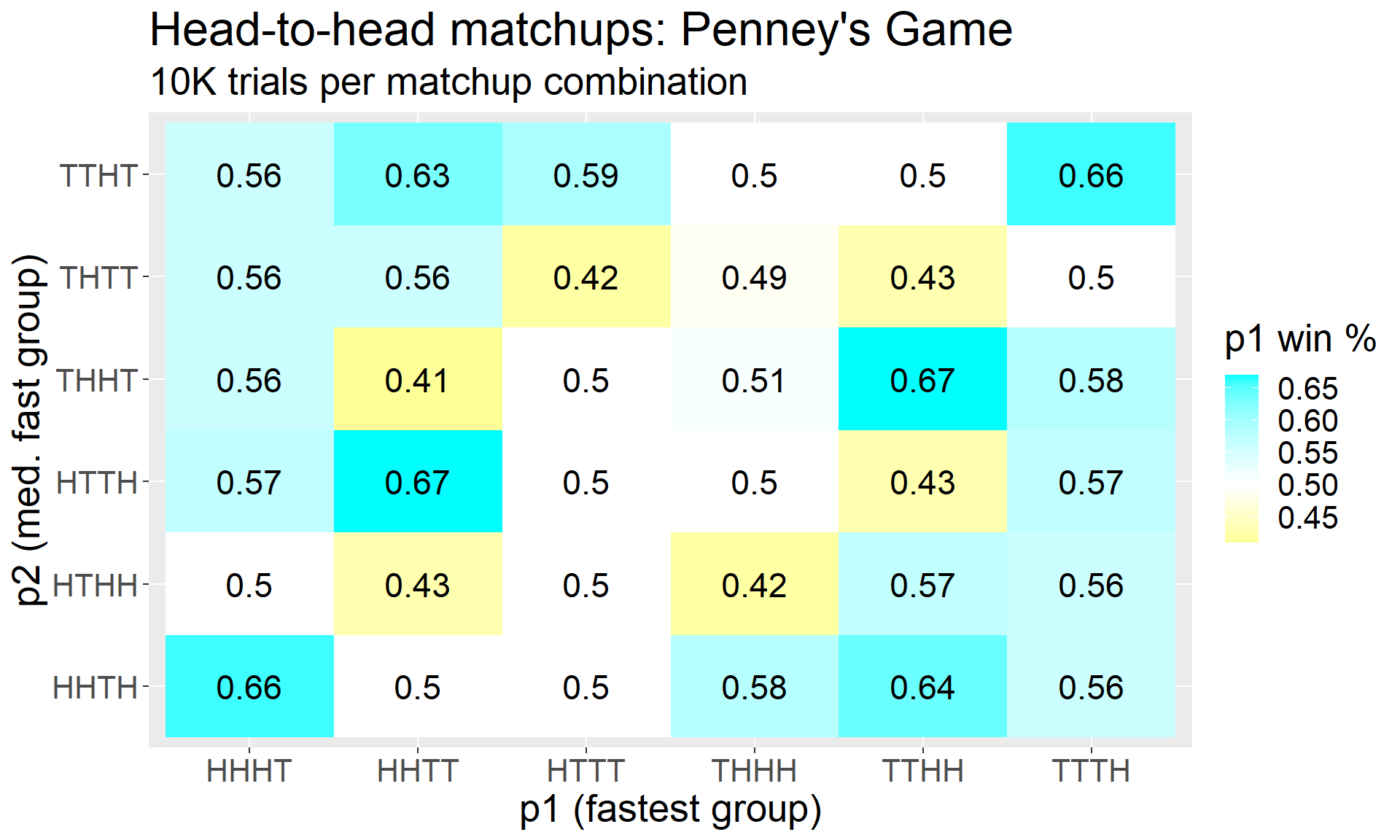
Next, let’s pit all the “fastest” group coins against the “med. fast” group coins competitively. There’s nothing special about this particular choice of tiers to compare, other than that it gives us lots of combinations to pit against each other.
A few coins in the “fastest” group do indeed dominate those in the “med. fast” group – but not all of them. HHTT, HTTT, THHH, and TTTH all have a competitive disadvantage against at least one coin from the allegedly lower tier.
Goodbye, Reasonable Conjecture… we hardly knew ye.
The Big Lesson
The most obvious lesson is that Penney’s Game is weird – which, sure. That’s at least the third time we’ve learned that particular lesson. More generally, we might use this as a reminder that probability is home to lots of counterintuitive results.
But I think the most important part of this story comes back to the idea of a mathematical laboratory. The Penney’s Game saga so far naturally invites several questions for further exploration, such as:
If I know the sequence chosen by my opponent, how do I build the sequence with the best advantage over it?
Can a shorter sequence (like TTT) ever have a faster wait time than a longer sequence (like HTHH)?
We’ve actually seen that the answer is no for sequences of length 3 and 4, but what about longer sequences?
Is there any kind of pattern in the expected wait times as the sequence lengths increase?
Can a longer sequence ever have a direct head-to-head competitive advantage over a shorter sequence?
Exploration cultivates an expectation of enchantment. Explorers are excited by the thrill of finding the unexpected, especially things weird and wonderful. It’s why hikes through unfamiliar terrain entice us, why unexplored caves beckon to us, why the strange creatures of the deep-sea ocean floor fascinate us – what else may be lurking down there? There’s similar enchantment to be found in the zoo of strange discoveries in math.
Anyone with any level of expertise in probability (including none), and the ability to write code, can engage in investigations like those above. Thanks to Monte Carlo simulations, the joy of exploration in Penney’s Game can suddenly become accessible as a new class of explorers are invited to broaden the scope of who can partake in the beauty of mathematics. This is the way that Monte Carlo simulations can function as a mathematical laboratory; they can be used as a vessel for exploration and discovery.
If I could change one thing about my own experience working toward my PhD in Mathematics, I would have embraced Monte Carlo simulations much earlier in my career. I was able to construct them as a graduate student, but since I had never considered them in a particularly structured way, I tended not to reach for that tool when working on problems. In hindsight, I think engaging more in simulations early in my career could have sharpened my intuition, confirmed difficult theoretical calculations, and maybe even suggested new theorems to try to prove.
To Be Continued…
And yet, Monte Carlo simulations are also limited in scope. The ability of simulations to suggest conjectures is profound; their ability to prove those conjectures is flimsy at best. They typically fall short of showing why things are the way they are.
In Penney’s Game, some of the “why” questions might include: